Artificial Intelligence is no longer optional knowledge for developers. It’s quickly becoming core to modern software engineering.
Whether you’re building chatbots, productivity tools, or large-scale systems, understanding the fundamentals of how AI models work will give you a serious advantage in 2025 and beyond as we head further into an AI-driven economy.
In this post, we’ll cover 10 essential AI and machine learning concepts that every developer should know. These aren’t buzzwords. They’re the foundations you’ll encounter when building AI-powered apps.

Watch the Video?
Before we get started, if you prefer video, here you go:
Otherwise, continue reading…👇
1. AI Model Parameters
When you see models described as 2B, 7B, or 40B parameters, what does that actually mean?
Parameters are the weights in a neural network. So a neural network starts with these random, adjustable numbers called parameters (or, again, weights as you may have heard them called).
And during training, the model is fed a lot of data (like images or text), it makes a prediction, checks how far off it is, and then adjusts its weights slightly to improve next time or reduce that error. This is called fine-tuning.
More parameters generally mean a more capable model, able to handle complex reasoning and generate better responses.
But there’s a tradeoff: bigger models demand more GPU memory, more compute, and usually respond slower.
So when you see those parameter numbers, think of it as a balance between power and efficiency. A 7B model might run on a consumer GPU, while a 40B model could require enterprise-level hardware.
In short, parameters reveal the true size of the model and help you judge if it’s powerful enough for your goals while still fitting your hardware.
👉 Check out my in-depth blog post on AI Model Parameters, homelab recommendations, and how to choose the right model.
2. Quantization
AI models are made up of billions of little numbers called weights, as we just discussed. Each weight is stored with maximum detail or at full precision, like a high-resolution photo: sharp, but very large.
Quantization is like compressing those images.
Instead of storing every number in full detail, we store them in a smaller format. The picture looks almost the same, but the file size drops dramatically.
Why does that matter?
Well, it makes models smaller and faster, so you can run big ones on consumer GPUs.
With 4-bit quantization, a 30-billion-parameter model can drop from 80GB of VRAM to roughly 20GB.
The trade-off is a little loss in accuracy or nuance — like a compressed JPEG versus the original.
Here are some guidelines: If you’re building a chatbot, coding helper, or internal app, a quantized model is usually more than enough to fit your needs. But if you need the absolute best precision, say for research or some sort of mission-critical task, you’ll want full precision.
So quantization makes powerful models accessible without enterprise hardware, and for most apps, the trade is worth it.
👉 See my in-depth blog post in more detail on this as well, including where to find these quantized model files.
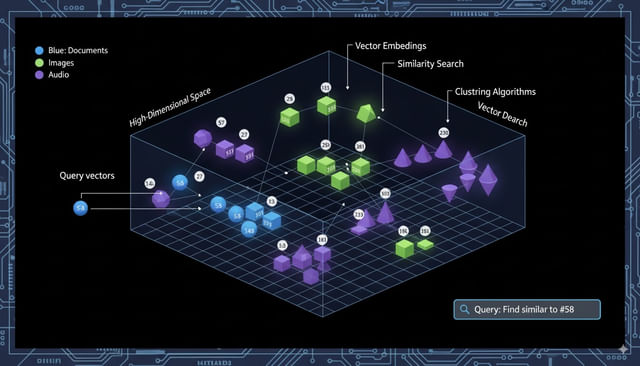
3. Embeddings and Vector Databases
Embeddings turn different types of data (like text, images, or audio) into vectors which are lists of numbers that capture their meaning and relationships.
Think of it this way: every word, sentence, or image gets a set of coordinates, a list of numbers. Similar ideas land close together, like ‘I like dogs’ and ‘I enjoy puppies’. Unrelated ones like ‘I like dogs’ and ‘my car broke down’ end up far apart.
And this is where vector databases come in. They store all these embeddings, or vectors, and let you quickly find the closest matches.
So, when do you actually need a vector database?
If it’s a small project with only a few hundred or maybe a few thousand embeddings, you can keep them in a normal database, or even just in memory. However, you’ll have to use a library like NumPy to calculate the distances.
But once you’re dealing with tens of thousands or millions of embeddings, a vector database like Pinecone, Weaviate, or open-source pgvector becomes essential. It takes care of fast similarity search, scaling, and indexing for you.
And, as a developer, you don’t need to know the math behind how embeddings are stored.
What matters is this: embeddings let AI compare by meaning, also called semantics, and vector databases make that comparison fast enough to power things like semantic search, chatbots with context, and recommendations.
4. RAG (Retrieval-Augmented Generation)
Large language models don’t actually know your private data. They only know what they were trained on.
Retrieval-Augmented Generation (RAG) is how we fix that.
Here’s how it works:
- You ask a question.
- The app you built around the model (not the model itself) searches an external knowledge source like a vector database full of documents, a PDF, or whatever.
- It pulls out the most relevant chunks.
- Those chunks get added to the model’s prompt, so the answer is based on your data in addition to the model’s training.
Here are some examples:
- Chatbots with company docs: RAG is the go-to method for grounding answers in your knowledge base.
- Big PDFs: Instead of the model making things up, your app splits the document into chunks, stores the embeddings, and then feeds back the right parts when a user asks something.
- Search with explanations: The system retrieves relevant passages, and the model turns them into clear, natural language answers — not just a list of search hits.
- Hallucination control: RAG cuts down on the model “making things up” by giving it real context first.
In short, RAG is the common pattern behind most AI apps that need to work with your data.
5. Inference
When you hear the word inference in AI, it simply means running a trained model to get results.
Training is the expensive part, building the model.
Inference is the practical part, calling it to generate text, classify an image, or answer a question.
It takes in your input (text, image, etc.), pushes it through all the layers of the neural network, and produces an output.
A few things to note:
- Every API call is inference. When you use OpenAI, Anthropic, or Hugging Face, you’re paying for inference time.
- Latency matters. A smaller
2Bmodel might respond almost instantly, while a70Bmodel could take a few seconds — and that difference shapes user experience. - Deployment choices around cost. Running inference on your own GPU might be cheaper but slower. Running it in the cloud may be faster, but more expensive.
- Tools like batching, caching, and quantization all exist to make inference faster and cheaper.
So yes, inference is just running the model to get an answer. The tricky part isn’t what inference is, but how to make it fast enough and cheap enough to use in real apps.
Understanding the costs and trade-offs helps you design smoother, more reliable systems.
6. Tokens & Context Windows
When you use an AI model, you’ll hear a lot about tokens.
A token is just a chunk of text, usually a word, part of a word, or punctuation, that the model processes. You can actually go to OpenAI’s Tokenizer tool and see exactly how tokens are broken down and counted.
And the context window is how many tokens a model can handle at once. Think of it as the model’s working memory.
Here are some things to consider as a developer:
- Cost: API pricing is based on tokens — more tokens = higher bill.
- Limits: A small window means you can’t feed long documents or maintain a long chat history.
- App Design: You may need to chunk, summarize, or trim input to fit under the limit.
And how big are the context windows at the time of this post?
GPT-5 offers over 200,000 tokens which could equate to a few hundred pages of text.
Google Gemini 2.5 Pro provides up to 1 million tokens, basically book-sized, with plans to take it up to 2 million soon.
And Claude offers around 200,000 tokens, with, I believe, more in newer model versions.
💡 Note: the context window refers to the combined total of input + output tokens. So if your Gemini input is 900K tokens, there’s only room for 100K output.
As a developer, choose larger context windows if you’re building apps that handle long PDFs, conversation history, or RAG pipelines. And stick with smaller windows if your use case is short chats, queries, or if you want faster responses and lower costs.
7. Guardrails
“When people talk about guardrails in AI, and you WILL hear this term, they’re talking about the filters and rules that decide what a model will or won’t say.
You’ll run into them in two main places:
From the AI provider: If you’re using OpenAI, Anthropic, or Gemini and your prompt gets blocked or redacted, that’s a guardrail. These are built-in, and you can’t turn them off. That’s why sometimes you’ll see the model reply: ‘Sorry, I can’t help with that.’
In your own app: You can layer on your own guardrails with tools like Guardrails AI or LangChain. This might mean forcing JSON output to follow a schema, filtering out profanity, or blocking topics your product doesn’t allow.
So, in regard to the provider side, since guardrails are non-negotiable there, design your UX so refusals don’t break the flow. Wrap refusals in friendly, helpful messaging or give alternatives when they happen.
But on your side, add whatever rules you need for structure, safety, and compliance before going live.
Guardrails are the safety layer around model outputs. Providers set some, and you’ll probably add more if you want your app to be reliable in production.

8. Function Calling
One of the most practical features in modern AI APIs is function calling. You think it’s a term I’m just making it up, but you can go now and read OpenAI’s function calling guide.
Instead of just generating text, the model can actually call a function you define.
For example, you register getWeather(city). If a user asks ‘What’s the weather in Paris?’, the model doesn’t guess — it outputs structured JSON saying: ‘Call getWeather with city=Paris.’ Your code runs the function, gets the real data, and the model can use it in the reply.
Why do you need functions and function calling?
- Standard in APIs: OpenAI, Anthropic, and Gemini all support it now.
- Structured output: Instead of crossing your fingers with prompt hacks, structured output gives you solid, predictable JSON your app can work with.
- Trigger real actions: This is how AI can kick off workflows, send emails, or update databases — not just chat.
And where are these important?
Well, AI agents use function calling under the hood to chain multiple steps together.
And you’ve definitely seen it as an integral part of MCP.
So, function calling is the building block that makes AI interactive. It’s how we move from chatbots to real assistants that can do things, not just talk about them.”
9. Memory
When people say an AI has memory, it sounds nice, but it’s not built into the model.
By default, models are stateless.
They only know what you send in that one request.
If you want memory, you have to build it yourself or use an out-of-the-box solution.
In practice, memory just means saving past interactions somewhere, a database, a vector store, or session state, and then feeding the important pieces back in on the next request.
So you prompt the model, it responds, and in your next response, you need to include the history either by appending it on directly or pulling it from a database or storage of some sort.
And what makes memory so important is the simple fact that it’s what makes chatbots feel personal and consistent.
So, as a developer, you’ll have to decide how to store it: full transcripts, summaries, or embeddings for semantic recall.
Also, remember you’re bound by the context window, so memory isn’t endless.
So when someone says an AI has memory, what they really mean is the developer-engineered persistence.
10. Cost & Rate Limits
One of the first things you run into when building with AI APIs is cost and rate limits.
Here’s how it works: most providers charge by tokens.
Every word you send in, and every word the model sends back, costs money.
Long prompts, giant documents, or using huge context windows all push your costs up.
And then there are rate limits, which are caps on how many requests you can make per minute or per day.
So, as a developer, you need to consider:
- Keeping prompts lean. Cut the fluff, summarize history, and don’t send more than you need.
- Batching and caching. Don’t pay twice for the same call — reuse results.
- Choosing the right model. Use big, expensive ones for heavy lifting and smaller ones for quick tasks.
- Adding retries, backoffs, and queues to handle limits gracefully so your app slows down instead of crashing.
So cost and rate limits actually shape how you design your app, so plan around them early.
Conclusion
These 10 AI and machine learning concepts are the building blocks of real-world AI development in 2025.
If you already know them, you’re well prepared for the rapidly evolving landscape. If not, start with these ten because understanding these fundamentals will help you build faster, cheaper, and more reliable AI-powered apps and ultimately keep you as a valuable worker in this quickly changing landscape.
This page may contain affiliate links. Please see my affiliate disclaimer for more info.